Epita:Algo:Course:language Memo
Contents
|
Algorithm: presentation
The language presented here is the one used during algorithmic courses and td (imperative part) of the two years of preparatory classes of Epita. There are two "levels" of use: in course, where we directly use abstract types with their operations, and in td, where the abstract types are represented using structured types and where the operations are implemented as routines (the next logical step is the implementation machine, which is almost reduced to the translation in the selected language).
General structure of an algorithm
Here is the general structure of an algorithm. Like many imperative languages, it is composed of two distinct parts : declarations and instructions.
algorithm algo_identifier
<declarations part>
begin
<instructions part>
end algorithm algo_identifier
The declaration part is detailed later in this section, the instruction part will be specified later (see section instructions').
Typographic Note: in all the pages of this site, the algorithmic parts are described as follows:
- keywords
- identifiers
- <items to be fixed>
- [optional items]
- ... to indicate that the current structure can be repeated.
Algorithm Writing rules
Alphabet and vocabulary -- The "words" of the language
As for all languages (and not only in coding, even in Klingon), we must, at first, define an alphabet (Characters used) and the words which allow us to construct statements (for example, instructions in this case). Two kinds of words will be present in an Algorithm : Keywords, predefined words in the language, and identifiers, words created to "name" the variables, the types, the routines... For the latter, it exists very strict rules of construction.
Identifiers naming conventions
An identifier is a word created to name :
- a constant,
- a type
- a variable,
- a procedure,
- a function,
- the main algorithm.
The 'identifiers can only contain characters lying within the following ranges :
- 'a'..'z'
- 'A'..'Z'
- '0'..'9'
We can also use tha character '_' (underscore).
To construct an identifier, you must respect the following rules :
- It can't start by a digit.
- Algorithmic language algorithmique doesn't make difference between uppercase and lowercase.
- To be used (in the instruction) any identifier must be declared before (in the declaration part).
- An identifier has to be different from a keyword, this is to avoid any ambiguity.
- to finish, to simplify the writing and reading of algorithms, it is strongly recommended to use explicit identifiers.
keywords
keywords are used to construct algorithms, declarations and instructions. Those ones are predefined in the language. As for identifiers, no difference is done between uppercase and lowercase.
keyword list of language :
| algorithm | div | global | parameters | while | then | record | until | procedure |
| types | otherwise | and | local | for | variables | constants | do | mod |
| case | begin | end | not | if | decreasing | function | or | else |
Word dividers -- Special symbols
The structure of the algorithm, the statements, and the instructions is made so that there is no need of special separators (the different parts are simply in sequence). All begun parts are explicitly finished. We only use the comma "," as word divider for the parameter lists in the routicomme séparateur pour les listes de ne calls. However, the newline is necessary before starting a new instruction or a new declaration.
A number of characters and character combinations have special meaning for the algorithmic language. Here's the list:
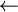
|
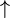
|
. | , | : | /* | */ | < | > | <= | >= | <> | = | + | - | * | / | ( | ) |
Comments
It is possible to insert comments into the algorithm
at any place. Ignored by the compiler, the comments are not part of the algorithm and do not affect the course thereof. So this is just for understanding! Comments are delimited
by pairs of symbols / * and * /.
Declarations part
Here we declare all what we need for the algorithm : constants, types, variables as well as the routines (procedures and functions).
<declaration part>:
<constant declarations> <type declarations> <variable declarations> <routine declarations>
The order of the declarations is important, and it can not be changed. We will see here the constants, types and variables declarations (the routines will be seen in the procedures and functions section)
Constant declarations
constants
constant_ident = <value>
...
A constant can not be modified in the algorithm.
Type declarations
types
type_ident = <type definition>
...
Here are specified all the user defined types.
Variables Declarations
Les variables contiennent les données manipulées par l'algorithme. Lors de la déclaration on doit leur attribuer un type. Celui-ci doit être défini (on applique ici une règle très importante valable partout : on ne peut utiliser que ce qui est déjà connu! Dès lors, lorsqu'on veut utiliser quelque chose, il faut s'assurer que cela a déjà été déclaré ou est prédéfini dans le langage.) : prédéfini dans le langage, ou défini par l'utilisateur (voir section types). Dans ce dernier cas le type doit obligatoirement avoir été déclaré avant !
variables
ident_type ident_variable1, ident_variable2, ...
...
Chaque ligne contient la liste des variables du type spécifié (on peut pour plus de clarté définir plusieurs listes pour un même type). Attention, il n'y a aucun symbole entre le type et les identifiants!
Les types
Les types prédéfinis
Les types prédéfinis en langage algorithmique sont :
| - entier | nombres entiers signés | 42 |
|---|---|---|
| - reel | nombres flottants signés | 0.154 |
| - octet(mot) | nombres entiers non signés sur un (deux) octet(s) | |
| - booleen | énumération définissant les données vrai et faux | |
| - caractere | caractère ANSI sur un octet | 'a' |
| - chaine | chaîne de caractères | "lapin" |
Les types définis par l'utilisateur
Énumérations
Les énumérations sont des listes d'identifiants représentant de manière lisible une suite de valeurs ayant un lien logique.
Déclaration
types
ident_enum = (ident_valeur1, ident_valeur2, ...)
Utilisation
Les identifiants sont utilisés comme des constantes et peuvent donc être directement affectés à des variables du type énuméré.
Tableaux
Les tableaux permettent d'associer dans une même variable plusieurs données de même type.
Déclaration
- Une dimension
types
ident_tableau = <entier> ident_type_elts
L'entier peut être directement une valeur, ou un identifiant de constante entière. Le type des éléments peut être un type prédéfini, ou un type utilisateur qui doit avoir été déclaré avant.
- Deux dimensions ou plus
Dans ce cas il suffit de donner autant d'entiers que de dimensions.
types
ident_tableau = <entier1> x <entier2> ... ident_type_elts
Utilisation
L'accès à un élément d'un tableau se fait en indiquant la liste des indices correspondant à chaque dimension.
ident_var[<indice1>, <indice2>, ...]
On obtient alors une variable du type des éléments.
Les enregistrements
Un enregistrement est une structure qui regroupe dans une même entité logique un ensemble de données de types différents.
Déclaration
types
ident_enreg = enregistrement
ident_type1 ident_champ11, ident_champ12, ...
ident_type2 ident_champ21, ident_champ22, ...
...
fin enregistrement ident_enreg
Utilisation
Pour accéder au contenu d'un enregistrement, on utilise la notation à point : on donne le nom de l'enregistrement (l'identifiant de la variable), suivi d'un point (.) et du nom du champ auquel on désire accéder.
ident_var.ident_champ
Pointeurs typés
Un pointeur est une donnée qui contient l'adresse en mémoire d'une autre donnée. Ainsi, plusieurs pointeurs peuvent pointer sur la même donnée, s'ils contiennent la même adresse. Le pointeur typé pointe sur une donnée dont le type est défini dans le même bloc de déclaration. Particularité de cette déclaration : c'est la seule pouvant utiliser un identifiant de type non déclaré précédemment.
Déclaration
types
ident_pointeur = ident_type_pointé
Utilisation
Accès à l'élément pointé :
ident_var
Les instructions
Préliminaire : Les expressions
Une expression représente une succession de calculs ; elle peut faire intervenir des constantes, des variables, des fonctions et des opérateurs. Les expressions sont utilisées dans tout l'algorithme : dans les affectations, en paramètre des routines, dans les structures de contrôles...
Expression : syntaxe
Une expression peut être :
| - une valeur | 42 |
| - une variable | x |
| - une constante | C |
| - un appel de fonction | cos(x) |
| - <expression> OpérateurBinaire <expression> | 32 + x |
| - OpérateurUnaire <expression> | non A |
| - (<expression>) | (a + 15) |
| ... |
Les opérateurs
Les opérateurs arithmétiques
- Les classiques :
| - (unaire) | Changement de signe |
| + | Addition |
| - | Soustraction |
| * | Multiplication |
| / | Division flottante |
Les opérandes peuvent être du type entier (le résultat est entier) ou reel (le résultat est reel), sauf pour la division flottante, où le résultat sera toujours de type reel (Voir la concordance des types pour les cas mixtes).
- La division entière :
| div | Division entière |
| mod | Modulo (reste de la division entière) |
Ces opérateurs ne fonctionnent qu'avec des entiers !
Les opérateurs logiques (et binaires``)
Les opérandes sont booléens, on a alors une opération logique. Le résultat est un booléen. Les expressions booléennes sont utilisées comme conditions dans les structures de contrôles.
| div | Division entière |
| non | négation logique ( ) )
|
| et | et logique (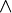 ) )
|
| ou | ou logique (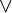 ) )
|
| oue | ou exclusif |
Rappels : Avec a et b des booléens ou des expressions booléennes :
| - a et b | n'est vrai que si a est vrai et b est vrai | est faux dès qu'un des deux est faux |
| - a ou b | n'est faux que si a est faux et b est faux | est vrai dès qu'un des deux est vrai |
| - a oue b | est vrai si un des deux seulement est vrai | est équivalent à a<>b |
Important : Les opérateurs et et ou sont séquentiels : si l'évaluation de la première opérande suffit à donner le résultat, la deuxième n'est pas évaluée. Ainsi, si a est faux, a et b sera faux, sans que b n'ait été évalué.
Note : On utilisera les mêmes opérateurs sur des entiers non signés mot ou octet, on a alors des opérations sur bits. Les opérateurs fonctionnent de la même manière, le vrai correspondant à 1, le faux à 0.
Les opérateurs relationnels
Les deux opérandes doivent être de types compatibles. Le résultat est toujours de type booleen : vrai ou faux.
| = | égal |
| <> | différent |
| < | inféreur à |
| > | supérieur |
| <= | inférieur ou égal |
| >= | supérieur ou égal |
La concaténation de chaînes
L'opérateur "+" pourra être utilisé avec les chaînes de caractères et les caractères pour la concaténation.
Règles d'évaluation des expressions
Priorité des opérateurs
Par ordre décroissant :
| opérateurs unaires | - non |
| opérateurs multiplicatifs | * / div mod et |
| opérateurs additifs | + - ou |
| opérateurs relationnels | = < <= > >= <> |
Les expressions entre parenthèses sont entièrement évaluées avant d'intervenir dans la suite des calculs.
Concordance de type
Un opérateur binaire`` ne peut porter que sur deux valeurs du même type. Une exception a lieu lorsqu'une valeur est réelle et l'autre entière. Dans ce cas la valeur entière est convertie en une valeur réelle. Cette règle s'applique pour les opérateurs arithmétiques (+, -, *, /) et ceux de comparaisons.
L'affectation
Cette instruction permet d'affecter une valeur à une variable. La valeur peut être n'importe quelle expression de type compatible avec la variable.
- Syntaxe
ident_var
avec ident_var :
- un identifiant de variable
- une référence à un élément d'un tableau
- une référence à un champ d'enregistrement
- un objet pointé
Note : dans la suite ident_var représentera ces quatre éléments.
- Fonctionnement
ident_var
- Une valeur (une expression) ne peut en aucun cas figurer à gauche d'une affectation.
- Une variable figurant à droite d'une affectation (et plus généralement dans toute expression) doit obligatoirement contenir une valeur.
Les appels aux fonctions et procédures
L'appel d'une procédure ou d'une fonction (routine) se fait par son nom suivi, s'il y a lieu, de la liste des arguments placés entre parenthèses. Il faut respecter l'ordre de déclaration des paramètres. Lorsque le passage se fait par adresse (paramètre global), l'argument doit obligatoirement être une variable. S'il est passé par valeur (paramètre local), il peut s'agir d'une expression quelconque (voir Les paramètres). La distinction entre les différents paramètres sera vue en détail dans le chapitre consacré aux procédures et fonctions.
Appel de procédure : une instruction
L'appel de procédure est une instruction à part entière :
ident_procedure (param1, param2, ...)
Exemples de procédures : les entrées-sorties
- Les procédures d'affichage : ecrire -- ecrireSansRetour
ecrire ("lapin", x)
affiche la chaîne lapin``, suivi du contenu de la variable x (à condition que x contienne une valeur).
ecrireSansRetour (12+a)
affiche la valeur de l'expression 12+a, sans retourner à la ligne.
- La procédure de lecture : lire
lire (x)
affecte à la variable x la valeur saisie.
Appel de fonction : une expression
Une fonction est une routine qui retourne une valeur. L'appel de fonction sera donc utilisable comme n'importe quelle autre valeur (dans une expression, en paramètre d'une routine, ...). Par exemple dans une affectation :
ident_var
Note : Un appel de fonction seul n'est pas une instruction !
Les structures de choix
L'alternative : si ... alors ... sinon ... fin si
- Syntaxe
si <expression booleenne> alors
<instructions>
[sinon
<instructions> ]
fin si
Remarque :La partie sinon <instruction> est facultative.
Attention : Le fin si est obligatoire ! Il en sera de même pour toutes les instructions structurées : cette marque de fin doit être présente même si il n'y a qu'une seule instruction.
- Fonctionnement
Si la condition (exprimée par l'expression booléenne) est vraie alors seule la suite d'instructions placée après le alors sera exécutée. Dans le cas contraire, si la partie sinon existe elle sera exécutée, si elle n'existe pas, rien ne se passe.
Choix multiples : selon ... faire
- Syntaxe
selon <expression> faire
<liste_expr> : <instructions>
...
[autrement <instructions>]
fin selon
<liste_expr> = une liste de valeurs (séparées par des virgules) pour l'expression.
L'expression doit être de type scalaire : les types entiers, le type caractere et les énumérations.
- Fonctionnement
Les instructions exécutées seront celles correspondant à la valeur (Attention, rien à voir avec le filtrage de caml !) de l'expression. Si celle-ci n'est pas dans une des liste, alors ce sera la partie autrement (si elle existe) qui sera exécutée.
Structures de répétition
Les répétitives
tant que ... fin tant que
- Syntaxe
tant que <expression booléenne> faire
<instructions>
fin tant que
- Fonctionnement
Les instructions sont répétées tant que la condition est vérifiée. Comme le test est au début, les instructions peuvent donc ne jamais être exécutées.
Attention : il est impératif que la condition devienne fausse à un moment. Pour cela il faut que l'expression booléenne contienne au moins une variable qui sera modifiée dans la boucle.
faire ... tant que
- Syntaxe
faire
<instructions>
tant que <expression booléenne>
- Fonctionnement
La condition est placée après les instructions, elles sont exécutées donc au moins une fois, et persistent tant que la condition reste satisfaite. Bien entendu, même contrainte quant à l'expression booléenne.
L'itérative : pour ... fin pour
- Syntaxe
Elle permet de répéter une série d'instructions un nombre déterminé de fois.
pour ident_var
- Fonctionnement
La variable est nécessairement de type scalaire : entier, caractère ou énumération. Les expressions de début et de fin doivent être compatibles avec elle. Elle prend successivement toutes les valeurs comprises entre les deux bornes (dans l'ordre décroissant si indiqué !). Elle ne peut pas être modifiée dans la boucle !
Les procédures et fonctions
Les paramètres
Locaux - Globaux
Toute routine peut définir des paramètres, qui sont autant de données en entrée, fournies lors de l'appel à la routine depuis un autre endroit de l'algorithme. La structure de ces paramètres est définie immédiatement après l'entête de la routine (comme indiqué dans la syntaxe des procédures et fonctions ci-dessous). On distingue deux catégories de paramètres : les locaux et les globaux.
- Les paramètres locaux indiquent que le paramètre effectif passé lors de l'appel à la routine sera en fait copié localement, et que la routine travaillera alors sur la copie locale (on parle de passage par valeur). De la sorte, toute modification effectuée par la routine ne sera pas répercutée sur la donnée passée en paramètre. Ce qui fait qu'un paramètre local peut recevoir une expression comme paramètre effectif, et non pas obligatoirement une variable.
- Les paramètres globaux ne gérèrent pas de copie locale du paramètre effectif. Ils ne font qu'un avec la donnée qui leur est passée. En appelant une routine qui a des paramètres globaux, il faut alors fournir pour ceux-ci un nom de variable existante, et non une expression, puisque la routine est susceptible de modifier la variable passée (on parle de passage par variable ou par adresse).
Déclaration des paramètres
La déclaration des paramètres se fait comme une déclaration de variables. Deux parties pour séparer les paramètres locaux des globaux :
parametres locaux
ident_type ident_param1, ident_param2, ...
...
parametres globaux
ident_type ident_param1, ident_param2, ...
...
Note : L'ordre de déclaration n'a pas d'importance, mais il ne peut y avoir qu'une seule déclaration de paramètres locaux et qu'une seule déclaration de paramètres globaux.
Déclaration des routines
Les procédures
Une procédure est une routine (un bloc de code) qui exécute un traitement puis rend la main. On peut ainsi isoler une partie de l'algorithme global et éventuellement l'appeler plusieurs fois en gardant un code structuré et modulaire.
- Syntaxe
algorithme procedure ident_procedure
[<declarations parametres>]
[<declarations>]
debut
<instructions>
fin algorithme procedure ident_procedure
Les déclarations locales
Les déclarations sont les mêmes que pour un algorithme simple, à l'exception des routines : si la procédure ou fonction en cours doit en appeler une autre, cette dernière doit avoir été déclarée avant (toujours selon le même principe "je ne parle que de ce que je connais" qui devrait être beaucoup plus souvent appliqué !). On peut donc déclarer des constantes, des types et des variables. Toutefois il est très rare de déclarer des constantes et des types locaux à une routine, ceux-ci devant être généralement partagés par tout l'algorithme (voir la partie Portée des identifiants ci-dessous). Pour les variables par contre, il est fortement conseillé de n'utiliser que des variables locales (déclarées dans la routine en cours) et non pas des variables globales (en fait ce n'est pas fortement conseillé : c'est obligatoire !).
Les fonctions
Une fonction est une routine (un bloc de code) effectuant un traitement et renvoyant une valeur.
- Syntaxe
algorithme fonction ident_fonction : ident_type_retourné
[<declarations parametres>]
[<declarations>]
debut
<instructions>
fin algorithme fonction ident_fonction
Le type retourné ne peut être qu'un type simple (entier et dérivés, réel, caractère, booléen, pointeur) ou une chaîne.
La procédure retourne
La fonction retourne une valeur au moyen de la procédure système retourne. Celle-ci doit donc obligatoirement figurer dans les instructions de la fonction.
Le retourne est débranchant : son exécution termine la fonction. Toute instruction placée après ne sera donc pas prise en compte. Cette propriété est quelquefois utilisée pour permettre la sortie d'un algorithme avant la fin. On trouvera donc la procédure retourne appelée sans arguments dans des procédures (voilà je l'ai dit...).
Il est très fortement déconseillé d'utiliser le "pouvoir débranchant" de retourne, cela ne plait pas du tout à votre chargée de TD ! (Arf! dit le WikiCoder Krisboul)
Portée des identifiants
La portée d'un identifiant est la partie de l'algorithme dans laquelle cet identifiant est reconnu conformément à sa déclaration, c'est-à-dire l'ensemble des lignes de codes dans lesquelles l'utilisation de cet identifiant fera référence à la donnée qu'il définit.
Un identifiant sera "visible" dans l'algorithme où il a été déclaré et dans tout sous algorithme appelé, mais jamais à un niveau plus haut.
Il est possible d'avoir des "conflits" de portée, c'est-à-dire qu'un niveau d'imbrication de routine déclare un identifiant portant le nom d'un autre identifiant existant à un niveau supérieur. La règle alors est la suivante : la version la plus proche (la plus profondément imbriquée) de l'identifiant a la priorité.
Une règle à ajouter pour la construction des identifiants : dans un même bloc de déclarations, deux identifiants ne peuvent être identiques. En revanche, s'ils sont déclarés dans des portées différentes, deux identifiants peuvent être identiques, mais ils engendrent alors un conflit de portée.
(Nathalie "Junior" Bouquet)